
L’Indépendance : la discipline simple de la complexité
Je ne sais pas pour vous, mais moi j’en ai marre que google, Facebook et compagnie me dirigent vers leurs autoroutes d’informations publicitaires
Enfin je vais mettre un bémol, je ne veux plus leur donner tout !
Je veux pouvoir leur donner en échange d’un service mais je veux pouvoir aussi me servir de la force du réseau sans rester dans les mailles du filet.
Cette problématique vous parait lointaine, c’est normal ça veut dire que vous êtes dans le bon moule.
Le jour ou vous ne correspondrez plus à la norme ou que votre pays se transforme en dictature, ou en temps guerre. Les choses se compliqueront et le web décentralisé et indépendant deviendra vital pour vous.
Pourquoi
Dans le contexte actuel, on observe cependant une centralisation d’Internet en ce qui concerne son infrastructure, ses services, son information. Ce phénomène est malsain et donne les plein pouvoirs à Google, Facebook, Microsoft, Amazon etc. Au delà du marketing et des échanges commerciaux le web d’aujourd’hui nous propulse dans un monde ultra-surveillé, où chacun perd son anonymat…
La quasi totalité des états procèdent à une surveillance généralisée de leurs populations.
Si vous n’avez rien à cacher en temps normal, quand le contexte change les enjeux de l’information sont cruciaux… Sans parler des journalistes, lanceurs d’alertes, combattant pour la démocratie ou pour la liberté qui tous les jours doivent se cacher pour rester en vie. Cf le guardian project
Nous avons négligé la gestion de nos données personnelles au profit de la gratuité de produit californien.
Aujourd’hui les états et les majors du Business se font plaisir en toute impunité.
Mon expérience
Depuis plusieurs années, je suis plusieurs mouvements liés à l’indépendance du web et de ses protocoles.
En 2002, passionné par le Référencement naturel je me suis très vite penché sur les standards, j’ai appliqué et appris les règles et la gouvernance du consortium de normalisation W3C.org.
En 2006, poursuivant le chemin initiatique des Internets et ayant vraiment envie de comprendre les enjeux de l’identité, je me suis intéressé un brin de temps à l’authentification décentralisée porté par le W3C, l’OpenID. J’ai croisé aussi la route de la philosophie Wiki en 2008 lors des rencontres d’Autrans. Un épisode qui m’a permis de voir la force d’une communauté et de son outil.
En 2010 on m’a parlé de web sémantique, un mystère, une curiosité, un nouveau monde ? Tim Berners Lee un des inventeurs du Web évangélisait les atouts du web intelligent.
L’idée est simple nous ne sommes pas obligés de transporter l’intelligence.
il permet aux machines de comprendre la sémantique, la signification de l’information sur le Web. Il étend le réseau des hyperliens entre des pages Web classiques par un réseau de lien entre données structurées permettant ainsi aux agents automatisés d’accéder plus intelligemment aux différentes sources de données contenues sur le Web.
En 2012 à la recherche de l’indépendance et de courant alternatif, on m’a présenté l’IndieWeb. Le nom m’a plu tout de suite.
IndieMark:
Your content is yours,
You are better connected,
You are in control.
L’objectif de cette organisation est de rendre l’Internet indépendant, comme le téléphone, le mail…
Le prochain RDV de cette jolie organisation sera à Berlin le 4,5 et 6 novembre 2016 chez Mozilla.
Pour participer à l’IndieWebCamp Berlin ci dessous :
Quand
- Vendredi (optional):
- Samedi:
- Dimanche:
one-hit-wonder ⏰- difference to LA is -8 hours on Saturday and -9 hours on Sunday
Où
Mozilla Berlin
Haus 10, Treppe 6
Voltastraße 5
13355 Berlin,
Germany
OpenStreetMap |
google map
[U8, Voltastraße]
See schedule for which rooms when (tba)
See this wiki for info about the venue.
- Cost: Free
URL
http://indiewebcamp.com/2016/Berlin
Les solutions
La redécentralisation d’Internet consiste à mettre les terminaux, les services et l’information à la périphérie du réseau.
Internet a été conçu comme un réseau de réseaux interconnectés dans lequel n’importe quel nœud du réseau peut communiquer avec tous les autres.
Je vous rapporte un compte rendu détaillé et je donne du temps à toutes les personnes qui souhaitent acquérir les bases de l’indépendance.
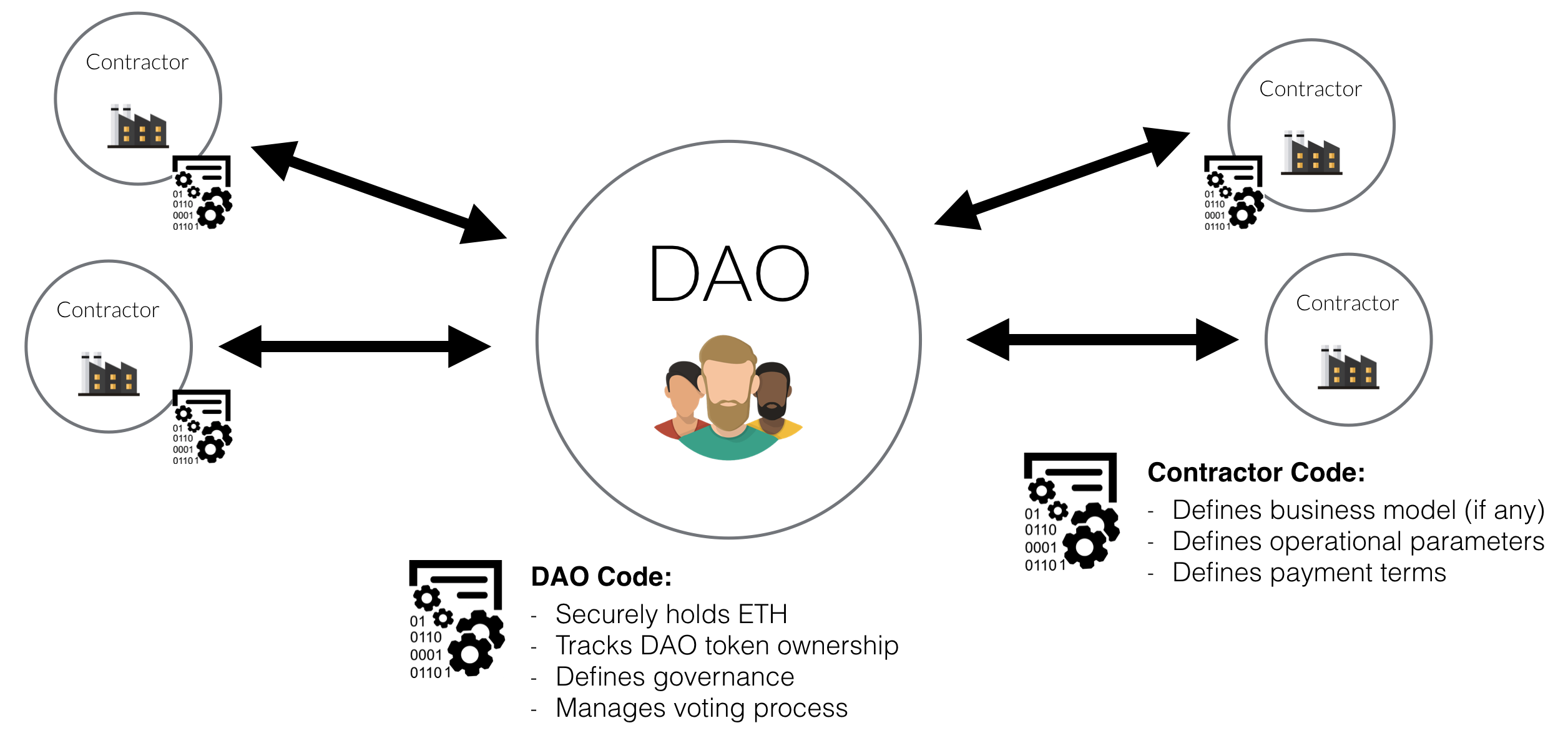
Découverte de la DAO 2016
Voilà un nouveau souffle, une innovation qui ferait la preuve qu’on peut se passer d’intermédiaire pour le financement de projets innovants et autres…
Le DAO est une organisation autonome Décentralisée « DAO » = « Decentralized autonomous organization »
Ce qui est encore plus important que Bitcoin, c’est la technologie sous-jacente la #Blockchain. Le potentiel de la crypto-monnaie est infini. Le concept du blockchain peut être étendue à d’autres domaines et rendre beaucoup plus facile la notion de confiance.
La possibilité de transactions de pair à pair va bientôt devenir une réalité. Imaginez les implications pour le commerce mondial, ou le financement de projets…
Ce qui explique mon intérêt pour DAOHUB !
Si on est moqueur on peut dire que DAO c’est un peu une monnaie décentralisée, une pincée social network connecting people, une pointe de Internet of things et un soupçon de OPenGov democracy avec un soubriquet de privacy.
Et pendant ce temps là, la levée de fonds pour la DAO, une forme de fond mutualiste qui se destine à soutenir des projets assez futuristes vient de dépasser les 3M d’Ether = environ 30M de dollars.
On est à l’endroit précis de la croyance, du pari, de la spéculation, de la prise de risque, de la création monétaire à la demande.
Ok, cela semble très pyramidale d’un coté mais tout à fait Bitcoinesque de l’autre, mais on vit là une énorme perspective de transformation de modèle économique, fin du modèle actuel et début de l’économie décentralisé sans intermédiaire.
C’est très concret, ça revient à miser sur la réussites de projets comme ceux de slock.it ou Mobotiq, et les bénéfices de la DAO seront directement liés à la réussite de ceux ci.
Tu investis dans la DAO, slock.it demande les fonds à la DAO, la DAO accepte suite à un vote, Slock.it développe l’universal sharing network avec l’argent de la DAO et si ça marche tu touches une commission lorsque que l’universal sharing network est utilisé.
Slock.it est un exemple, d’autres projets peuvent faire appel à la DAO.
Il sert aussi à créer un fond qui pourra financer des projets, suite à des propositions qui seront faite à la DAO et que les possesseurs des DAO tokens pourrons voter.
L’idée est bien sur d’avoir un retour sur investissement, qui reviendra soit aux investisseurs, soit à la DAO.
Le DAO est une organisation autonome Décentralisée « DAO » = « Decentralized autonomous organization » –
C’est un nouveau type d’organisation humaine jamais tentée. Le DAO est supporté à partir du code informatique immuable, imparable, et irréfutable #BlockChain exploité entièrement par ses membres, et alimentée en utilisant l’ETH qui crée des jetons DAO.
Plusieurs aspects de cette structure sont révolutionnaires :
– Inclusion: Le DAO exploite les contrats intelligents sur le blockchain Ethereum afin que toute personne, partout dans le monde peut être autorisé à participer. En échange de leur aide précoce, les participants reçoivent des jetons de DAO qui détiennent de nombreux avantages.
– Flexibilité: La DAO soutient les propositions qu’elle choisit pour leur caractère innovant, à livrer par les entrepreneurs. Certaines de ces propositions pourrait tenir aucune promesse de retour que ce soit (dans le cas d’un organisme de bienfaisance, par exemple), d’autres pourraient impliquer la construction de produits ou de services Le DAO pourrait alors utiliser à ses propres fins.
– Rentabilité et croissance: Les frais de DAO pour l’utilisation de ses produits ou services. Ce chiffre d’affaires est ensuite envoyé directement à l’OAC sous la forme de l’ETH. Le DAO a alors la possibilité d’accumuler cette ETH pour soutenir sa croissance, ou le redistribuer aux porteurs DAO Jeton comme une récompense.
– Gouvernance autonome: L’ETH détenu par Le DAO ne sera jamais géré de manière centralisée. Les porteurs DAO Jeton sont en mesure de voter sur les décisions importantes relatives à la gestion de la DAO, y compris le pouvoir de redistribuer son ETH entre eux.
Le DAO, représenté par des contrats à puce sur le blockchain Ethereum à l’adresse 0xbb9bc244d798123fde783fcc1c72d3bb8c189413, a l’intention de soutenir une série de propositions visant à créer des produits ou des services. Les porteurs DAO Jeton seront ensuite tirer parti de ces produits ou services, ou charger d’autres pour les utiliser.
The DAO a collecté plus de 2,9 millions d’ethers, en neuf jours. Cela correspond à plus de 27 millions de dollars au cours actuel ! Il s’agit d’ores et déjà du deuxième plus gros projet de crowdfunding de l’histoire.
La période de souscription, ou période de Création, est ouverte depuis le 1er mai 2016, et jusqu’au 28 mai 2016. Pendant cette période il est possible de créer des tokens DAO en envoyant des ethers au smart-contract de The DAO. En créant des tokens, vous participez à la création de cette organisation et vous pourrez participer aux votes sur l’octroi de ses fonds.
Après le 28 mai 2016, la phase de souscription sera terminée et il faudra acheter vos tokens sur une place de marché, possiblement plus cher cf l’histoire des bitcoins.
Cette période de création-souscription est divisée en trois phases :
– Une première phase de 14 jours pendant laquelle l’envoi d’un ether sur le contrat de la DAO donne droit à 100 tokens.
– Une seconde phase de 10 jours pendant laquelle le nombre de tokens reçus diminue progressivement chaque jour pour chaque éther envoyé.
– Une troisième phase de 4 jours pendant laquelle il faut envoyer 1,5 ether pour avoir droit à 100 tokens.
Si vous souhaitez participer à The DAO, il est conseillé d’envoyer vos ethers au contrat avant la fin de la première phase. Celle-ci se terminera le 14 mai 2016 à 11h environ.
Les points clés de cet événement sont décrits sur le site https://daohub.org.
Les étapes d’achat de tokens :
– la première, la plus simple, consiste à passer par le site MyEtherWallet. Elle peut être utilisée si vous avez créé votre wallet par l’intermédiaire du site
– La seconde est plus longue à mettre en place, mais elle offre plus de flexibilité : elle consiste à passer par l’Etherum Wallet, le logiciel officiel permettant de gérer un wallet Ethereum.
Moi je me tate, mais je pense acheter un petit Kg avant le 14 mai…
Il est l’Or de se transformer !
« le marché a 1000 milliards d’euros de potentiel de création de valeur d’ici à 2025 et on est bien décidés à en prendre un petit bout »
Depuis des mois on parle de transformation numérique, de transition digitale, de disruption, d’uberisation, d’économie on demand…

Beaucoup de gros mots (buzzworld) qui ne servent pas à tout le monde. Car dans la plupart des cas la première étape de la transformation numérique correspond à la la rationalisation de son système d’information et le partage agile des responsabilités dans la société. Un travail qui n’a pas encore été effectué dans toutes les entreprises.
Avez vous ?
1. un système de gestion client à jour => connaissance client / prospect
2. un process de vente éprouvé => animation commerciale multi canal
3. des indicateurs de performance => mesure de l’ensemble de l’activité via des cockpits
4. une gestion de projet / hiérarchisation plus horizontale => méthode agile
5. une communication transparente => sociale et engagée
Pour tout ceux qui n’ont pas intégré ces 5 points pas besoin de lire la suite 🙂
Pour les autres nous allons partager nos experimentACTIONS.
Depuis 2 ans nous vivons la transformation numérique sur nous et avec nos clients.
Nous nous interrogeons sur un phénomène qui s’immisce de plus en plus dans les conversations et qui inonde depuis quelques temps les médias spécialisés. Confère les couvertures de magazine « Changer ou mourir », « Où en êtes vous dans votre transition », « Il est temps de s’uberiser »…
Tous les jours il y a un nouveau manifeste, livre blanc et étude en tout genre.
Nous ne pensions pas que l’effet « transformation » prendrait autant et nous nous sommes même posé la question :
« C’est quoi cette F**** transition, de l’esbroufe ou une vraie rupture ? »
Pour nous la transformation numérique bouleverse les entreprises depuis l’avènement de l’informatique, l’arrivée d’Internet, le fonctionnement en réseau et l’usage du pair à pair. Le problème c’est que beaucoup de monde ont raté des chapitres ou des épisodes de la grande histoire des Internets.
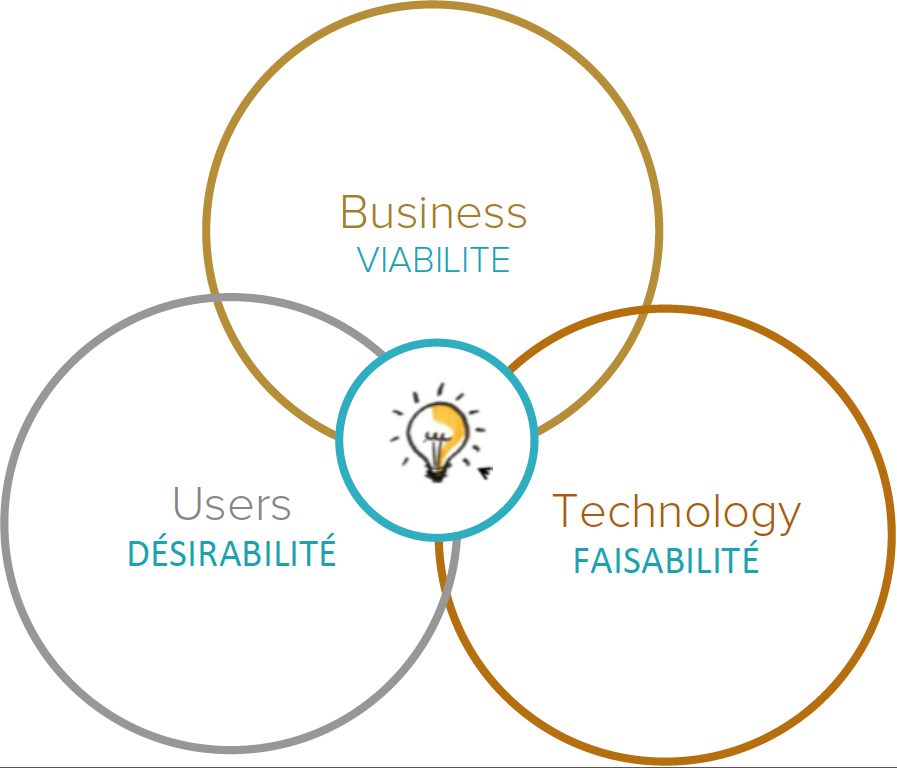
On joue le jeu, on ne crache pas dans la soupe. On vit bien une vraie rupture qu’on a schématisé de cette manière.
{kind=link}
La transformation numérique = (w)Technologie + (w)Homme + (p)Modèle économique
La technologie est au centre de tous les processus :
- Elle est de plus en plus accessible
- Elle évolue de manière exponentielle
- Elle permet de rationaliser n’importe quel écosystème
Les Hommes ne se managent plus de la même manière :
- Ils doivent s’adapter à la génération Y, et autres millennials… Le management doit s’horizontaliser et laisser à chacun un espace pour se révéler et s’épanouir.
- Ils doivent changer de structure organisationnel, l’organisation industrielle en silo laisse la place à la méthode agile et à l’itération… Les projets se découpent et s’emboitent plus facilement.
- Ils doivent se servir du code de l’autre (open source) et nous prototypons à volonté (Impression 3D).
- Ils doivent innover à plusieurs et de préférence en faisant appel à l’extérieur pour imaginer et concevoir les produits et services de demain (open innovation).
Les modèles économiques sont impactés par la technologie et les usages :
-
- Google donne accès à l’ensemble des biens de consommation et de ce fait supprime l’ensemble des intermédiaires.
- Facebook organise et forme les personnes à fonctionner en réseau, crée un nouveau statut social (e-reputation)
- Bittorrent apprend les notions basiques du pair à pair.
- Creative common permet de créer / gerer ses propres règles de droit d’auteur
- Bitcoin propose un moyens de paiement sécurisé et decentralisé
- Etc etc …
Grâce à ce socle, nous voyons apparaitre de nouvelle stratégie d’entreprise, incubation, rachat de start up, uberisation de service, développement de l’économie collaborative…
Les entreprises qui n’ont pas encore changé de cap, sont certainement en pleines réflexions.
A ces entreprises je leur dédie ces quelques mots.
Le plus dangereux est de rester immobile… Il faut apprendre à naviguer dans le brouillard… Il faut apprendre à tomber et se relever en permanence…Et si c’était mieux après !
.
CyberBobo face à l’économie on demand
Les Français raffolent de ces concepts et expérimentent de plus en plus ces modes de consommation. En effet nous gagnons en prix, en service et convivialité.
Les américains nous voient même comme un pays test qui pourrait montrer l’exemple au monde occidentalisé.
Cependant le grand écart est compliqué quand on doit concilier philosophie du partage, ultra libéralisme et defiscalisation massive.
A l’heure on entend parler de fin de CDI et de revenu universel on peut se demander
Attendons de voir comment vont se mélanger les cyber-hippies (puriste), les hippies 2.0 (libéraux) et les cyber-bobos (opportuniste).
Foire d’empoigne pour opportuniste / réel risque / réelle opportunité, on vit depuis quelque temps une remise en question intéressante
« comme il n’y aura pas de boulot pour tout le monde, il faudra bien mettre en place un revenu universel ».
Pour le moment le marché mondial de l’économie « on demand » représente 15 milliards en 2014, nous ne pouvons donc pas dire que la transformation numérique ait donnée naissance à un modèle économique qui met en péril l’économie traditionnelle. Peut être que ce sera le cas en 2025 (prévision d’un marché mondial de 335 milliards $) ou même avant mais pour le moment NON.
Mais si tout le monde parle de cette transition c’est qu’il y a certainement d’autres facettes à découvrir.
En prenant du recul, nous nous rendons compte que au delà de transformer l’entreprise, le numérique transforme les hommes (Transhumanisme), la politique (surveillance de l’internet), les usages…
Et c’est le serpent qui se mord la queue. Oui la technologie et Internet ont révolutionné le monde et ce n’est pas terminé…
Cependant et pour ne pas divaguer, il me semble que le paramètre principal qui change la donne actuellement dans l’entreprise est la vitesse d’exécution et la diffusion de cette transformation.
La transformation touche autant les TPE que le CAC 40.
Quel est l’impact de la transformation numérique sur les entreprises ?
Même si ça parait étrange pour un acteur qui vit et qui vend cette transformation, j’ai l’impression de l’avoir découvert ces derniers mois.
Tout s’accélère et les dirigeants / entrepreneurs qui avaient l’habitude d’avoir un coup d’avance sur la prospective, se retrouvent à naviguer dans le brouillard, sans boussole.
L’anticipation de l’évolution de son secteur n’est plus humainement prévisible.
La progression de GG / Facebook sur le marché de l’information. La disruption de marché par des nouveaux entrants comme Blablacar qui met en péril des lignes de TGV, Airbnb qui prend sa part de marché sur l’hôtellerie mondiale, amazon qui vous livre en 12h des produits sur lesquels ils sont prêts à perdre de l’argent…
Tous ces exemples sont la preuve qu’aujourd’hui toutes les entreprises doivent se remettre en question et tous les décideurs doivent apprendre à naviguer dans le brouillard.
Pour le moment la transformation de l’entreprise se focalise sur la « Performance et cost killing »
L’amélioration de la performance des entreprises (maitrise des données et processus) et le cost killing (maitrise des dépenses) représentent la grande partie des chantiers initiés dans l’entreprise.
Quelques entreprises s’intéressent, travaillent et communiquent sur les « Open Model » qui sont pour le moment une source de cohesion et un moteur positif de transformation.
Ce sont d’ailleurs ces thématiques qui sont les plus innovantes et qui permettront à l’entreprise de gagner la prochaine bataille.
Nous avançons vers un monde que personne ne peut prévoir ou imaginer, alors oui il est l’heure de se transformer même si on ne sait pas encore vraiment comment.
Le plus important pour le dirigeant / chef d’entreprise est d’initier un mouvement afin de préparer sa structure et sa tribu au futur changement.
« Fail fast, often and smart »
Filtre de vie @sncf

moi je trouve ces animations géniales !

lui il pense que c’est scandaleux de pédaler car il paye des impôts
Cannes 2014, Welcome To New York le dispositif #hackathon

Ce matin j’ai décidé en me réveillant de faire un hackathon welcome to new york.
Important
Pour les cinéphiles, j’ai regardé en diagonale le film, je ne trouve pas que ce soit un chef d’œuvre mais il fait le boulot. Ce qui est très intéressant c’est l’expérience TransMedia mis en place par Wild Bunch. Si vous veniez pour une critique de cinéphile, ce n’est malheureusement pas mon travail.
Je recherche toujours le nombre de téléchargement du film Welcome To New York sur les plateformes VOD (itunes, mytf1 etc) ? Merci d’avance
En 10 points :
– J’ai lu sur mon flux d’infos la chronologie de l’histoire construite par Vincent MARAVAL / Abel Ferrara l http://www.lemonde.fr/festival-de-cannes/article/2014/05/16/dsk-ferrara-croisette-new-york-un-aller-retour-en-trois-ans_4419880_766360.html
– J’ai testé du coup la VOD sur iTunes 6,95 euros j’aurais pu aller chercher dans torrent mais j’ai décidé de vivre l’expérience d’un utilisateur lambda.
– Premier sentiment je me dis film non distribué en France qui sort en VOD, waouh Vincent Maraval jette un pavé dans la marre…
– Je regarde le film en branchant mes jouets de veille, j’ouvre mes comptes twitter, je fais un plan d’action.
– J’ai un objectif en 6 heures de travail, faire un dimanche à 1000 visites, mais surtout un clin d’œil à @Danceti la reine de la croisette <3
– Ah enfin le dialogue commence « la bouillabaisse c’est la partouze des poissons » j’adore !
– Je cherche des influenceurs pour trouver des idées, des alliés, y’a pas grand monde.
– Je vais sur Facebook et là des choses intéressantes, pas d’activité, pas de page fan, gestion catastrophique…Il y a du potentiel.
– c’est la fin du film, j’ai aimé le Happening comme dirait Gégé #DédéLaSaumur
– Ne pas perdre l’objectif les 1000 visiteurs, il va falloir se servir de twitter / facebook / allociné.
Après 6h de travail :
J’aurais du tout miser sur un BOT 😉
Les mass médias bouchent toutes les entrées. Grosso modo le monde et rue89 se battent contre tous les autres.
La création de trafic se fait sur la tonalité éditoriale et positionnement des mots clés suivants, Welcome to New York torrent streaming et malheureusement antisémite…
Même FDESOUCHE commence à chauffer la salle.
welcome to new york @MARAVALV tagué par FDESOUCHE MARAVALV http://t.co/AZetvtrERR #Cannes14 #WelcomeToNewYork
— Nicolas Bermond (@nicolas2fr) 19 Mai 2014
Je crois que les médias l’ont bien compris.
Mes objectifs sont atteints par contre wild bunch ne communique pas sur les chiffres, ni les résultats.
@MARAVALV je suis preneur des chiffres, besoin pour mon article http://t.co/b1uHvYIjKm merci d'avance
— Nicolas Bermond (@nicolas2fr) 19 Mai 2014
48000 ventes premier jour, c'est l equivalent de 90000 entrées en recettes distributeur
— VINCENT MARAVAL (@MARAVALV) 19 Mai 2014
Fin du hackaton welcome to new york @nicolas2fr 1K – @MARAVALV – 48K http://t.co/zhkeYSv2cF
— Nicolas Bermond (@nicolas2fr) 19 Mai 2014
Merci, clôture du Hackathon
@nicolas2fr
Merci à cinefile pour son commentaire
J’ai vu le film également cette nuit, ravi de cette mise à disposition qui bouleverse un peu la donne de la distribution cinematographique française (et ça, rien que ça, ça fait du bien). Je suis surpris de voir que vous avez vu le film en tweetant, tentant de créer une page facebook….Est ce ainsi que l’on regarde et apprécie un film ? Mais soit..pourquoi pas… Ce qui me surprend le plus en réalité, c’est la somme d’articles qui ne traitent pas du matériau filmique mais cherche à le dézinguer sur des bases hypocrites (un sois disant antisémitisme, du sexe crûe -o mon dieu, du sexe ! quel scandale !-, la mise en relation fiction/réalité qui n’a pas lieu d’être : c’est un FILM !)…Quand à moi, j’ai tout simplement adoré ce film, un très grand ovni absluement incroyable au niveau de la gestion des ombres et lumières et de tout les éléments suggérés sur la psycho des personnages (les persos fictifs, pas réels…). Certaines scènes m’ont coupés le souffle par l’intelligence des dialogues et la finesse magistrale des acteurs : Jacqueline Bisset est incroyable, sublime et terriblement émouvante et juste. Depardieu est immense, hors norme (donc il sera détesté), il ne créve pas l’écran, il l’explose et le dynamite en finesse. Comment un corps si bourru et repoussant est-il capable de tant de sensibilité dans le visage ? C’est plus qu’un happening, c’est une performance…Ne pas le reconnaitre, c’est ne pas aimer le cinema selon moi…Quand à Abel Ferrara, il signe son plus beau film, le plus maitrisé, certaines scènes sont envoûtantes…Il y a un certain minimaliste qui tranche avec la richesse des dialogues, une gestion des lumières et des couleurs à tomber par terre, la première scéne de confrontation bisset/depardieu dans l’appartement est à ce titre une prouesse portée par des acteurs transcendants. Une autre scène, phénoménale est celle de l’instrospection de depardieu sur la terrasse, face aux buildings de manhattan, dément, fin, profond et magnifique…Les scènes de prison sont également superbes et minimales….Regarder ce film en pensant à DSK est la pire erreur à faire…Je suis terriblement attristé par l’accueil fait à ce film et ce qu’il révèle de l’état d’esprit Français actuel : aucun sens de la remise en question, cerveaux lobotomisés, aucun esprit d’analyse de l’objet filmique, à priori crétins sur Depardieu et que dire de ceux qui traite Ferrara de réal Has been ???? Oui, je suis triste…mes amis Français, où est votre esprit, pardon, votre ouverture d’esprit, votre sens critique, votre objectivité ???
J’ajouterais également que je suis outré et toujours attristé de voir les critiques des journalistes dans les grands quotidiens Français : une mécanique de dézinguage qui ne parle jamais du fond et de la forme, critiques creuses et tellement politiquement correct…oui, le journalisme Français est mort depuis longtemps…les critiques de cinema ne parlent pas de cinema…Tout cela est vraiment désolant…Regardez le film, c’est assurément un chef d’oeuvre tel que trés trés peu de réals Français seraient capable de mettre en scène…bravo à toute l’équipe…
Page fan officielle https://www.facebook.com/welcometonewyorkmovie
Dernières critiques Allociné